Hans-Juergen Schoenig: Using “Row Level Security” to make large companies more secure
Large companies and professional business have to make sure that data is kept secure. It is necessary to defend against internal, as well as external threats. PostgreSQL provides all the necessities a company needs to protect data and to ensure that people can only access what they are supposed to see. One way to protect data is “Row Level Security”, which has been around for some years now. It can be used to reduce the scope of a user by removing rows from the result set automatically. Usually people apply simple policies to do that. But, PostgreSQL Row Level Security (RLS) can do a lot more. You can actually control the way RLS behaves using configuration tables.
Configuring access restrictions dynamically
Imagine you are working for a large cooperation. Your organization might change, people might move from one department to the other or your new people might join up as we speak. What you want is that your security policy always reflects the way your company really is. Let us take a look at a simple example:
CREATE TABLE t_company
(
id serial,
department text NOT NULL,
manager text NOT NULL
);
CREATE TABLE t_manager
(
id serial,
person text,
manager text,
UNIQUE (person, manager)
);
I have created two tables. One will know, who is managing which department. The second table knows, who will report to him. The goal is to come up with a security policy, which ensures that somebody can only see own data or data from departments on lower levels. In many cases row level policies are hardcoded – in our case we want to be flexible and configure visibility given the data in the tables.
Let us populate the tables:
INSERT INTO t_manager (person, manager)
VALUES ('hans', NULL),
('paula', 'hans'),
('berta', 'hans'),
('manuel', 'paula'),
('mike', 'paula'),
('joe', 'berta'),
('jack', 'berta'),
('jane', 'berta')
;
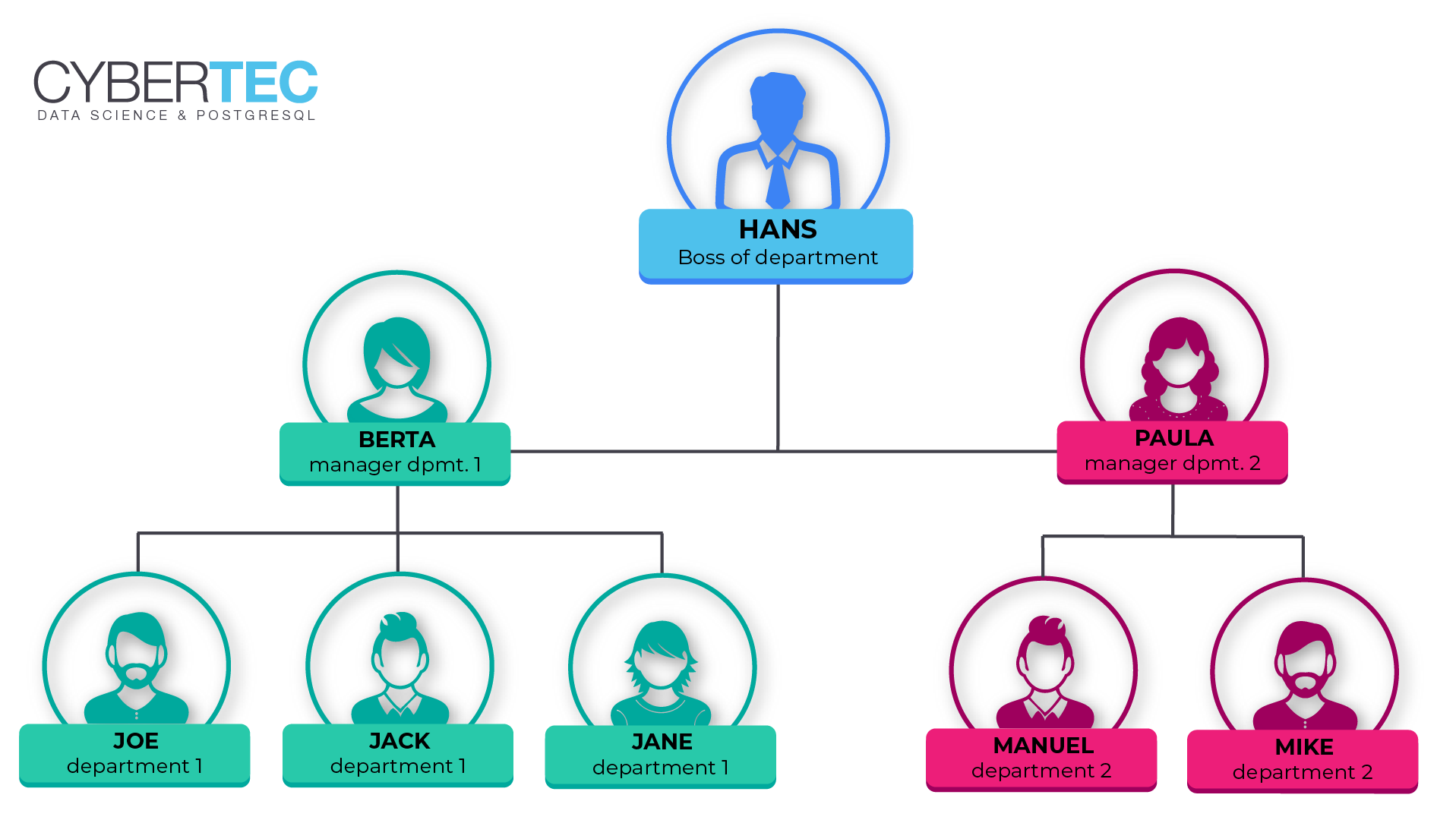
As you can see “hans” has no manager. “paula” will report directly to “hans”. “manuel” will report to “paula” and so on.
In the next step we can populate the company table:
INSERT INTO t_company (department, manager)
VALUES ('dep_1_1', 'joe'),
('dep_1_2', 'jane'),
('dep_1_3', 'jack'),
('dep_2_1', 'mike'),
('dep_2_2', 'manuel'),
('dep_1', 'berta'),
('dep_2', 'paula'),
('dep', 'hans')
;
For the sake of simplicity, I have named those departments in a way that they reflect the hierarchy in the company. The idea is to make the results easier to read and easier to understand. Of course, any other name will work just fine as well.
Defining row level policies in PostgreSQL
To enable row level security (RLS) you have to run ALTER TABLE … ENABLE ROW LEVEL SECURITY:
ALTER TABLE t_company ENABLE ROW LEVEL SECURITY;
What is going to happen is that all non-superusers, or users who are marked as BYPASSRLS, won’t see any data anymore. By default, PostgreSQL is restrictive and you have to define a policy to configure the desired scope of users. The following policy uses a subselect to travers our organization:
CREATE POLICY my_fancy_policy
ON t_company
USING (manager IN ( WITH RECURSIVE t AS
(
SELECT current_user AS person, NULL::text AS manager
FROM t_manager
WHERE manager = CURRENT_USER
UNION ALL
SELECT m.person, m.manager
FROM t_manager m
INNER JOIN t ON t.person = m.manager
)
SELECT person FROM t
)
)
;
What you can see here is that a policy can be pretty sophisticated. It is not just a simple expression but can even be a more complex subselect, which uses some configuration tables to decide on what to do.
PostgreSQL row level security in action
Let us create a role now:
CREATE ROLE paula LOGIN; GRANT ALL ON t_company TO paula; GRANT ALL ON t_manager TO paula;
paula is allowed to log in and read all data in t_company and t_manager. Being able to read the table in the first place is a hard requirement to make PostgreSQL even consider your row level policy.
Once this is done, we can set the role to paula and see what happens:
test=> SET ROLE paula; SET test=>; SELECT * FROM t_company; id | department | manager ----+------------+--------- 4 | dep_2_1 | mike 5 | dep_2_2 | manuel 7 | dep_2 | paula (3 rows)
As you can see paula is only able to see herself and the people in her department, which is exactly what we wanted to achieve.
Let us switch back to superuser now:
SET ROLE postgres; We can try the same thing with a second user and we will again achieve the desired results: CREATE ROLE hans LOGIN; GRANT ALL ON t_company TO hans; GRANT ALL ON t_manager TO hans;
The output is as expected:
test=# SET role hans; SET test=> SELECT * FROM t_company; id | department | manager ----+------------+--------- 1 | dep_1_1 | joe 2 | dep_1_2 | jane 3 | dep_1_3 | jack 4 | dep_2_1 | mike 5 | dep_2_2 | manuel 6 | dep_1 | berta 7 | dep_2 | paula 8 | dep | hans (8 rows)
Row level security and performance
Keep in mind that a policy is basically a mandatory WHERE clause which is added to every query to ensure that the scope of a user is limited to the desired subset of data. The more expensive the policy is, the more impact it will have on performance. It is therefore highly recommended to think twice and to make sure that your policies are reasonably efficient to maintain good database performance.
The performance impact of row level security in PostgreSQL (or any other SQL database) cannot easily be quantified because it depends on too many factors. However, keep in mind – there is no such thing as a free lunch.
If you want to learn more about Row Level Security check out my post about PostgreSQL security.
The post Using “Row Level Security” to make large companies more secure appeared first on Cybertec.
postgresql
via Planet PostgreSQL https://ift.tt/2g0pqKY
September 24, 2019 at 09:43AM
